R alap funkcionalitását csomagba (package) szervezett programokkal, beépített függvényekkel és objektumokkal bővíthetjük tovább. Ilyen csomagokból több ezer létezik, amellyel nagyon megkönnyebbítjük a munkánkat.
A kibővített funkciókat a csomag telepítésével és betöltésével tehetünk elérhetővé.
R csomagok telepítése R studioban:
Tools -> Install packages

---1
x <- margin.table(HairEyeColor, c(1, 2))
assocplot(x, main = "Relation between hair and eye color")

---2
tN <- table(Ni <- rpois(100, lambda = 5))
barplot(tN, col = "gray")

---3
boxplot(count ~ spray, data = InsectSprays, col = "lightgray")

---4
x <- 10 * 1:nrow(volcano)
y <- 10 * 1:ncol(volcano)
filled.contour(x, y, volcano, color = terrain.colors)

---5
z <- 2 * volcano
x <- 10 * (1:nrow(z))
y <- 10 * (1:ncol(z))
persp(x, y, z, theta = 135, phi = 30, col = "yellow3", scale = FALSE, ltheta = -120, shade = 0.75, border = NA, box = FALSE)

---6
sunflowerplot(iris[, 3:4])

---
library(networkD3)
# Load package
library(networkD3)
# Create fake data
src <- c("A", "A", "A", "A",
"B", "B", "C", "C", "D")
target <- c("B", "C", "D", "J",
"E", "F", "G", "H", "I")
networkData <- data.frame(src, target)
# Plot
simpleNetwork(networkData)

---
library(networkD3)
# Load data
data(MisLinks)
data(MisNodes)
# Plot
forceNetwork(Links = MisLinks, Nodes = MisNodes,
Source = "source", Target = "target",
Value = "value", NodeID = "name",
Group = "group", opacity = 0.8)

--- Sankey diagram minta
library(networkD3)
URL <- paste0(
"https://cdn.rawgit.com/christophergandrud/networkD3/",
"master/JSONdata/energy.json")
Energy <- jsonlite::fromJSON(URL)
# Plot
sankeyNetwork(Links = Energy$links, Nodes = Energy$nodes, Source = "source",
Target = "target", Value = "value", NodeID = "name",
units = "TWh", fontSize = 12, nodeWidth = 30)
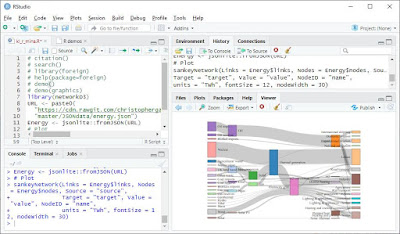
--- Szöveg felhő minta (2014 évi keresztnevek)
library(tm)
library(SnowballC)
library(wordcloud)
library(RColorBrewe)
adatok <- read.table("nevek.CSV", header = T, sep = ";");
windows();
wordcloud(adatok$Nevek,adatok$freq, random.order=FALSE, colors=brewer.pal (8,"Dark2"))

Csomagok leírása
– a read.csv vagy általánosabb read.table függvény segítségével csv, txt vagy egyéb strukturált szöveges állományokat olvashatunk be, nagyobb állományok gyors beolvasásához pedig a külön telepített readr csomagot vagy a data.table csomag fread függvényét használhatjuk.
– a foreign csomag lehetőséget biztosít a dbf fájlformátumon túl az általánosan használt egyéb adatelemző programok egyedi fájlformátumait olvasni, mint például az SPSS sav vagy a SAS által használt ssd és xport, továbbá az újabb haven csomag is számos kereskedelmi program formátumát támogatja, úgy mint a SAS sas7bdat és sas7bcat, az SPSS sav és por vagy a Stata dta fájljait.
– Excel fájlok legegyszerűbben a readxl csomag segítségével olvashatók, amely nagy előnye, hogy sem Java, sem Perl függőségekkel nem rendelkezik, így egyszerűen telepíthető, de a fejlettebb funkciók eléréséhez sokszor megkerülhetetlen valamelyik Java alapú csomag,
például a openxlsx használata, amely formázott Excel táblák írására is alkalmas.
– a DBI csomag egy általános adatbázisréteget biztosít a felhasználók számára, amely segítségével kényelmesen tudunk kapcsolódni például MySQL (RMySQL), Postgres és Amazon Redshift (RPostgreSQL), Oracle (ROracle) MS SQL Server (RSQLServer) vagy egyéb adatbázisokhoz ODBC (RODBC) vagy JDBC (RJDBC) kommunikációs csatornákon keresztül.
csomag segítségével.
A tisztított adatok elemzése előtti adattranszformációk (például adatok rendezése, szűrése, aggregálása, származtatott változók létrehozása, adathiány kezelése, imputálás, táblák összekapcsolása stb.) során már az alap R telepítés is számos hasznos függvényt biztosít, például egy mátrix sorain vagy oszlopain végzett műveletek elvégzésére az apply függvénycsalád segítségével vagy a rowSums, colSums stb. vektorizált megoldásokkal, de a hatékonyabb és felhasználóbarát szintaxis érdekében érdemesebb egyéb csomagokkal is megismerkednünk.
– a data.table csomag az R-ben általánosan használt data.frame adattömb oszlopműveletekre optimalizált kiterjesztése, amely az alap R telepítéshez képest sokkal gyorsabb és hatékonyabb működést tesz lehetővé nagyobb adatbázisokkal való munka során egy SQL-szerű szintaxis segítségével, és különböző táblák komplex összekapcsolásaira (például overlap, rolling vagy non-eque join) is lehetőséget biztosít.
– a magrittr csomag által biztosított „pipe” (cső, csővezeték) operátorra épülő,valamint dplyr csomag, amely egyrészt a data.table-hez hasonló gyors működést, másrészt olvashatóbb kódot tesz lehetővé az R függvények egymásba ágyazása helyett, a UNIX-ban megszokott pipe operátor segítségével a függvények kimenetét újabb függvényeknek adja át sorról sorra.
– a reshape2 és tidyr csomagok az ún. long (hosszú) és wide (széles) táblák átalakítására nyújtanak lehetőséget a dcast és melt függvények segítségével, amely többek között a modellezés vagy adatvizualizációhoz szükséges adatformátum előállítása során bizonyul hasznosnak.
https://rextester.com/l/r_online_compiler
https://paiza.io/projects/i53OrV-M26lwg2o3AsLjiw?language=r
https://rdrr.io/snippets/
A kibővített funkciókat a csomag telepítésével és betöltésével tehetünk elérhetővé.
R csomagok telepítése R studioban:
Tools -> Install packages

Minta diagramok:
---1
x <- margin.table(HairEyeColor, c(1, 2))
assocplot(x, main = "Relation between hair and eye color")

---2
tN <- table(Ni <- rpois(100, lambda = 5))
barplot(tN, col = "gray")

---3
boxplot(count ~ spray, data = InsectSprays, col = "lightgray")

---4
x <- 10 * 1:nrow(volcano)
y <- 10 * 1:ncol(volcano)
filled.contour(x, y, volcano, color = terrain.colors)

---5
z <- 2 * volcano
x <- 10 * (1:nrow(z))
y <- 10 * (1:ncol(z))
persp(x, y, z, theta = 135, phi = 30, col = "yellow3", scale = FALSE, ltheta = -120, shade = 0.75, border = NA, box = FALSE)

---6
sunflowerplot(iris[, 3:4])

---
library(networkD3)
# Load package
library(networkD3)
# Create fake data
src <- c("A", "A", "A", "A",
"B", "B", "C", "C", "D")
target <- c("B", "C", "D", "J",
"E", "F", "G", "H", "I")
networkData <- data.frame(src, target)
# Plot
simpleNetwork(networkData)

---
library(networkD3)
# Load data
data(MisLinks)
data(MisNodes)
# Plot
forceNetwork(Links = MisLinks, Nodes = MisNodes,
Source = "source", Target = "target",
Value = "value", NodeID = "name",
Group = "group", opacity = 0.8)

--- Sankey diagram minta
library(networkD3)
URL <- paste0(
"https://cdn.rawgit.com/christophergandrud/networkD3/",
"master/JSONdata/energy.json")
Energy <- jsonlite::fromJSON(URL)
# Plot
sankeyNetwork(Links = Energy$links, Nodes = Energy$nodes, Source = "source",
Target = "target", Value = "value", NodeID = "name",
units = "TWh", fontSize = 12, nodeWidth = 30)

--- Szöveg felhő minta (2014 évi keresztnevek)
library(tm)
library(SnowballC)
library(wordcloud)
library(RColorBrewe)
adatok <- read.table("nevek.CSV", header = T, sep = ";");
windows();
wordcloud(adatok$Nevek,adatok$freq, random.order=FALSE, colors=brewer.pal (8,"Dark2"))

Csomagok leírása
Adatok beolvasására használatos csomagok.
– a read.csv vagy általánosabb read.table függvény segítségével csv, txt vagy egyéb strukturált szöveges állományokat olvashatunk be, nagyobb állományok gyors beolvasásához pedig a külön telepített readr csomagot vagy a data.table csomag fread függvényét használhatjuk.
– a foreign csomag lehetőséget biztosít a dbf fájlformátumon túl az általánosan használt egyéb adatelemző programok egyedi fájlformátumait olvasni, mint például az SPSS sav vagy a SAS által használt ssd és xport, továbbá az újabb haven csomag is számos kereskedelmi program formátumát támogatja, úgy mint a SAS sas7bdat és sas7bcat, az SPSS sav és por vagy a Stata dta fájljait.
– Excel fájlok legegyszerűbben a readxl csomag segítségével olvashatók, amely nagy előnye, hogy sem Java, sem Perl függőségekkel nem rendelkezik, így egyszerűen telepíthető, de a fejlettebb funkciók eléréséhez sokszor megkerülhetetlen valamelyik Java alapú csomag,
például a openxlsx használata, amely formázott Excel táblák írására is alkalmas.
– a DBI csomag egy általános adatbázisréteget biztosít a felhasználók számára, amely segítségével kényelmesen tudunk kapcsolódni például MySQL (RMySQL), Postgres és Amazon Redshift (RPostgreSQL), Oracle (ROracle) MS SQL Server (RSQLServer) vagy egyéb adatbázisokhoz ODBC (RODBC) vagy JDBC (RJDBC) kommunikációs csatornákon keresztül.
Az adatok ellenőrzésére és tisztítására használatos csomagok.
A validate csomag egyszerűen meghatározható szabályrendszerek alkalmazására nyújt lehetőséget beolvasott adatainkon, amely szabályok automatizált felderítésére is lehetőségünk nyílik a deductivecsomag segítségével.
A tisztított adatok elemzése előtti adattranszformációk (például adatok rendezése, szűrése, aggregálása, származtatott változók létrehozása, adathiány kezelése, imputálás, táblák összekapcsolása stb.) során már az alap R telepítés is számos hasznos függvényt biztosít, például egy mátrix sorain vagy oszlopain végzett műveletek elvégzésére az apply függvénycsalád segítségével vagy a rowSums, colSums stb. vektorizált megoldásokkal, de a hatékonyabb és felhasználóbarát szintaxis érdekében érdemesebb egyéb csomagokkal is megismerkednünk.
– a data.table csomag az R-ben általánosan használt data.frame adattömb oszlopműveletekre optimalizált kiterjesztése, amely az alap R telepítéshez képest sokkal gyorsabb és hatékonyabb működést tesz lehetővé nagyobb adatbázisokkal való munka során egy SQL-szerű szintaxis segítségével, és különböző táblák komplex összekapcsolásaira (például overlap, rolling vagy non-eque join) is lehetőséget biztosít.
– a magrittr csomag által biztosított „pipe” (cső, csővezeték) operátorra épülő,valamint dplyr csomag, amely egyrészt a data.table-hez hasonló gyors működést, másrészt olvashatóbb kódot tesz lehetővé az R függvények egymásba ágyazása helyett, a UNIX-ban megszokott pipe operátor segítségével a függvények kimenetét újabb függvényeknek adja át sorról sorra.
– a reshape2 és tidyr csomagok az ún. long (hosszú) és wide (széles) táblák átalakítására nyújtanak lehetőséget a dcast és melt függvények segítségével, amely többek között a modellezés vagy adatvizualizációhoz szükséges adatformátum előállítása során bizonyul hasznosnak.
Adat kezelésre, feldolgozásra használatos csomagok.
Bár R-ben összetettebb adatstruktúrák kezelése, feldolgozására az rlist csomag ajánlható, amellyel listákon belül szűrhetünk, rendezhetünk vagy alakíthatjuk át, illetve lehetőség szerint transzformálhatjuk adattömb-formátumúra a további elemzésekhez adatainkat.R online editorok:
https://www.jdoodle.com/execute-r-onlinehttps://rextester.com/l/r_online_compiler
https://paiza.io/projects/i53OrV-M26lwg2o3AsLjiw?language=r
https://rdrr.io/snippets/
Megjegyzések
Megjegyzés küldése